Efficiency in Language Model Pre-training
Learning Curves Across Datasets and Model Sizes
Training large language models is compute- and data-intensive, limiting optimisation in resource-constrained settings and increasing environmental impact. In this work, we investigate how dataset composition, model size, and training budget interact during small-scale pre-training of decoder-only transformers. We train LLaMA-based models of three sizes (20M, 60M, and 180M parameters) on three curated datasets: TinyStories, BabyLM, and a composite English corpus constructed from diverse open-domain sources. Using token-based anchors ranging from 25M to 2B tokens, we derive learning curves and evaluate both formal and functional linguistic competence. Formal competence is measured with BLiMP, and functional competence, defined as natural language understanding (NLU), is evaluated on a subset of GLUE and SuperGLUE. The experimental grid results in 351 evaluated model instances.
Although small relative to current large-scale systems, these models allow controlled analysis of pre-training dynamics under explicit compute constraints.
Finding 1: Dataset Selection Strongly Influences Performance
We find that dataset selection strongly influences model performance. Models trained on the composite corpus consistently outperform those trained on BabyLM and TinyStories. This relative ordering is already observable early during pre-training and remains stable throughout training. In several cases, a smaller model trained on a structurally richer corpus outperforms a larger model trained on a more limited one. Early anchor performance appears representative of converged behaviour, suggesting that compute-aware model comparison can be supported by early-stage evaluation.
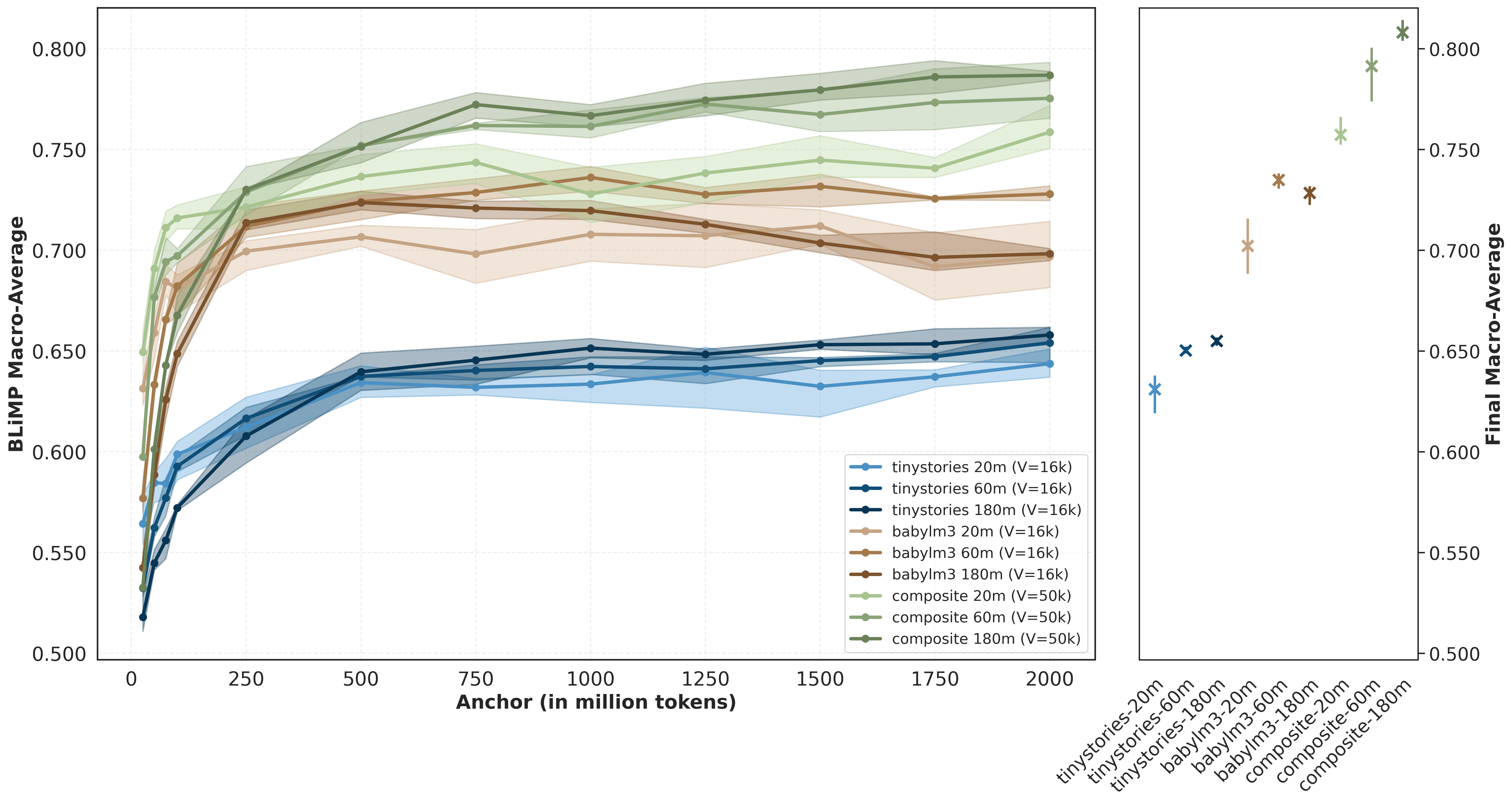
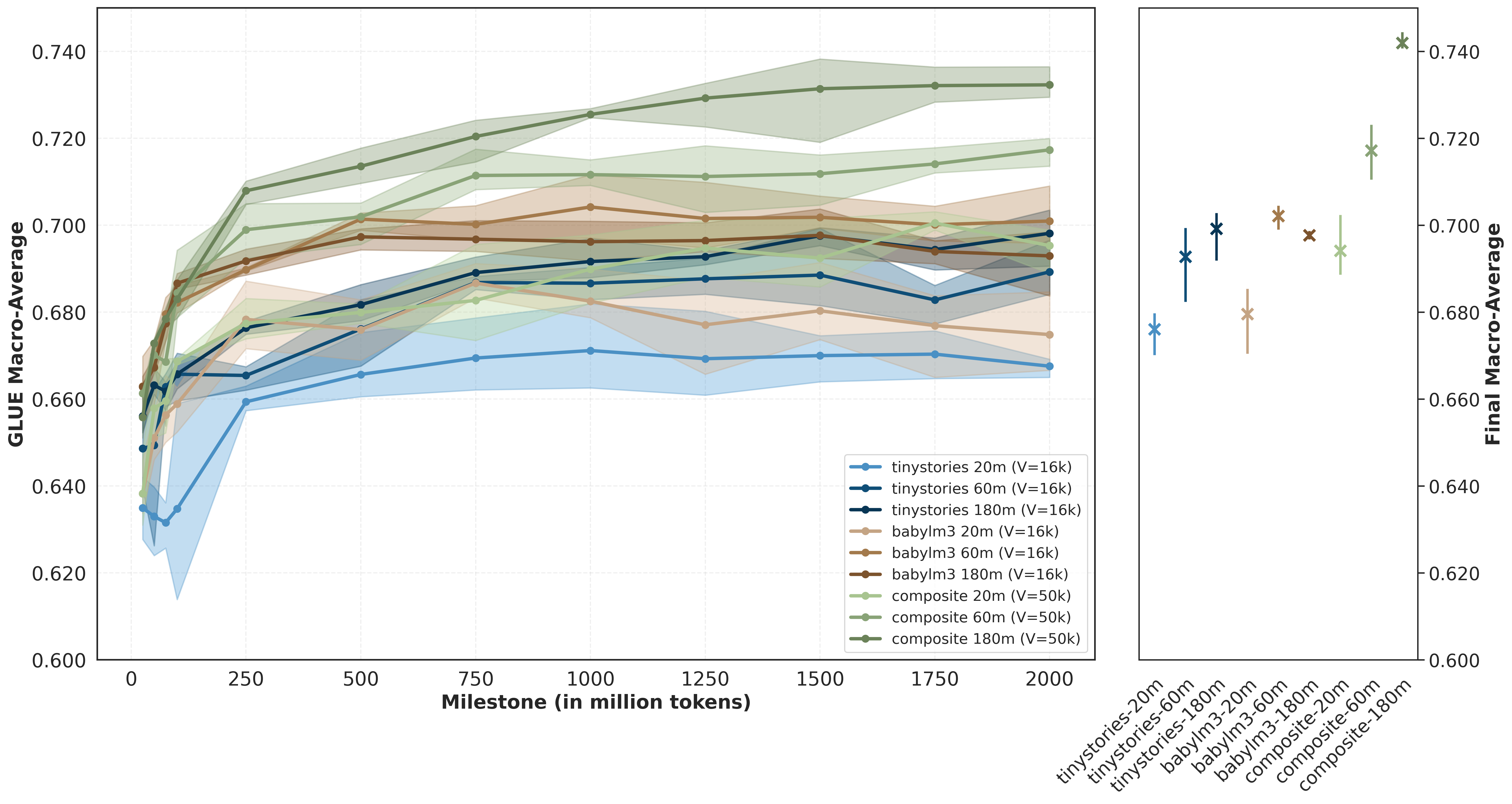
Finding 2: Scaling Gains Depend on Data Diversity
The effect of model scaling is dataset dependent. For the composite corpus, larger models yield consistent improvements across anchors. For BabyLM, scaling gains are weaker and occasionally unstable, and for TinyStories they are limited. In both BLiMP and downstream heatmaps, richer-data settings present an upward shift in mean scores together with a reduced interquartile range (IQR), indicating more uniform performance across linguistic groups and tasks. These results suggest that additional model parameters are most effectively utilised when paired with sufficient structural and lexical diversity.
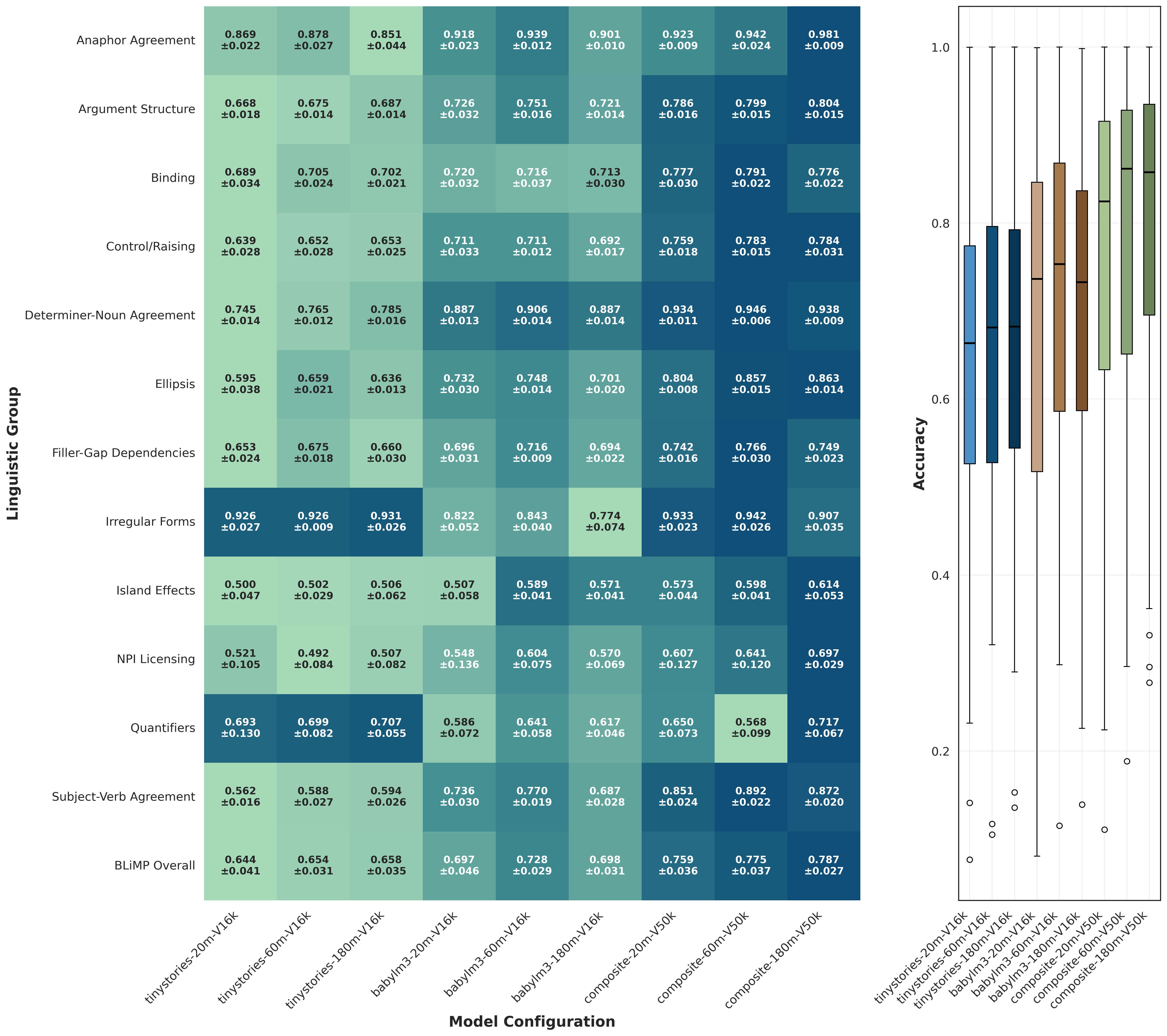
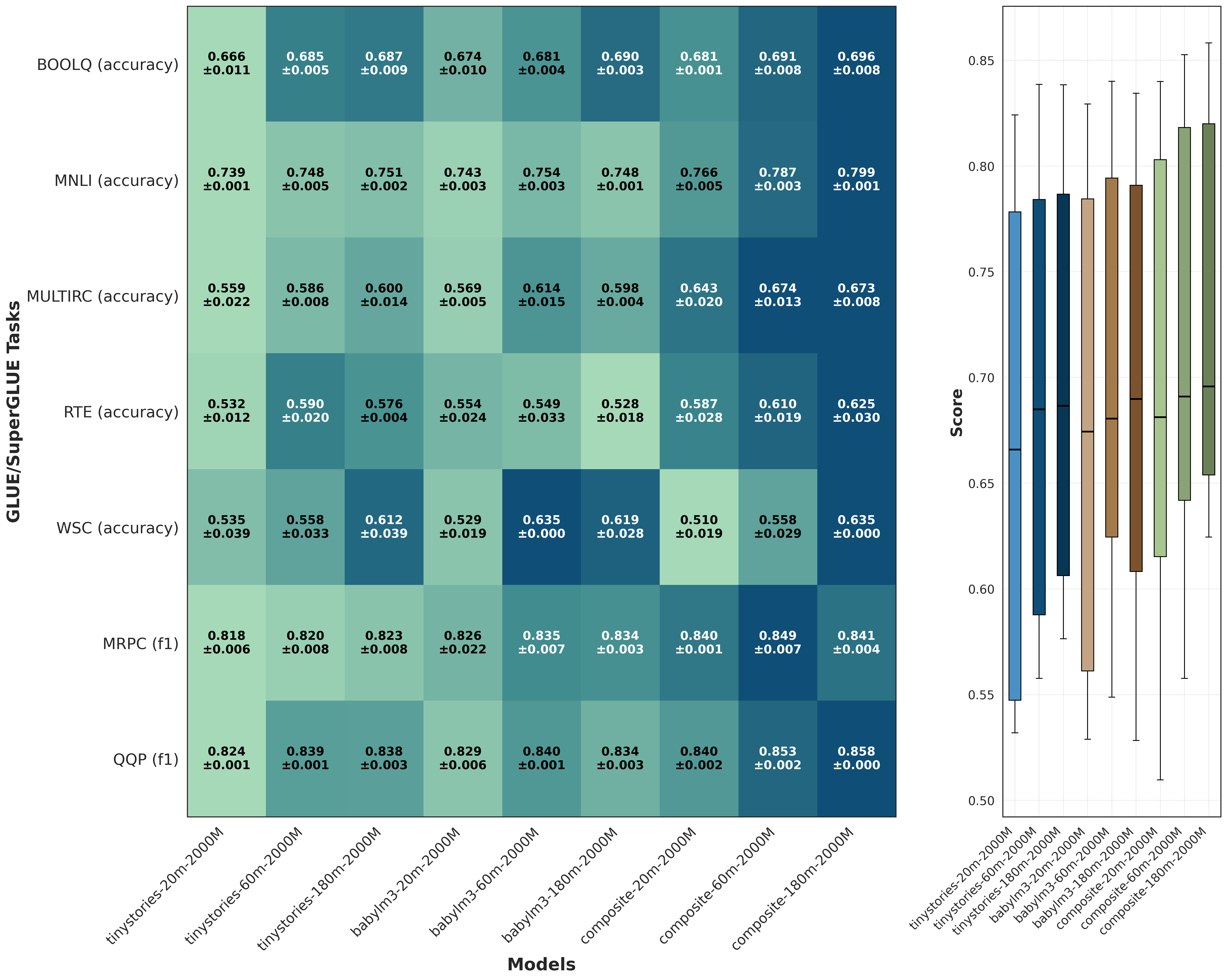
Finding 3: Early Anchors Predict Final Model Ranking
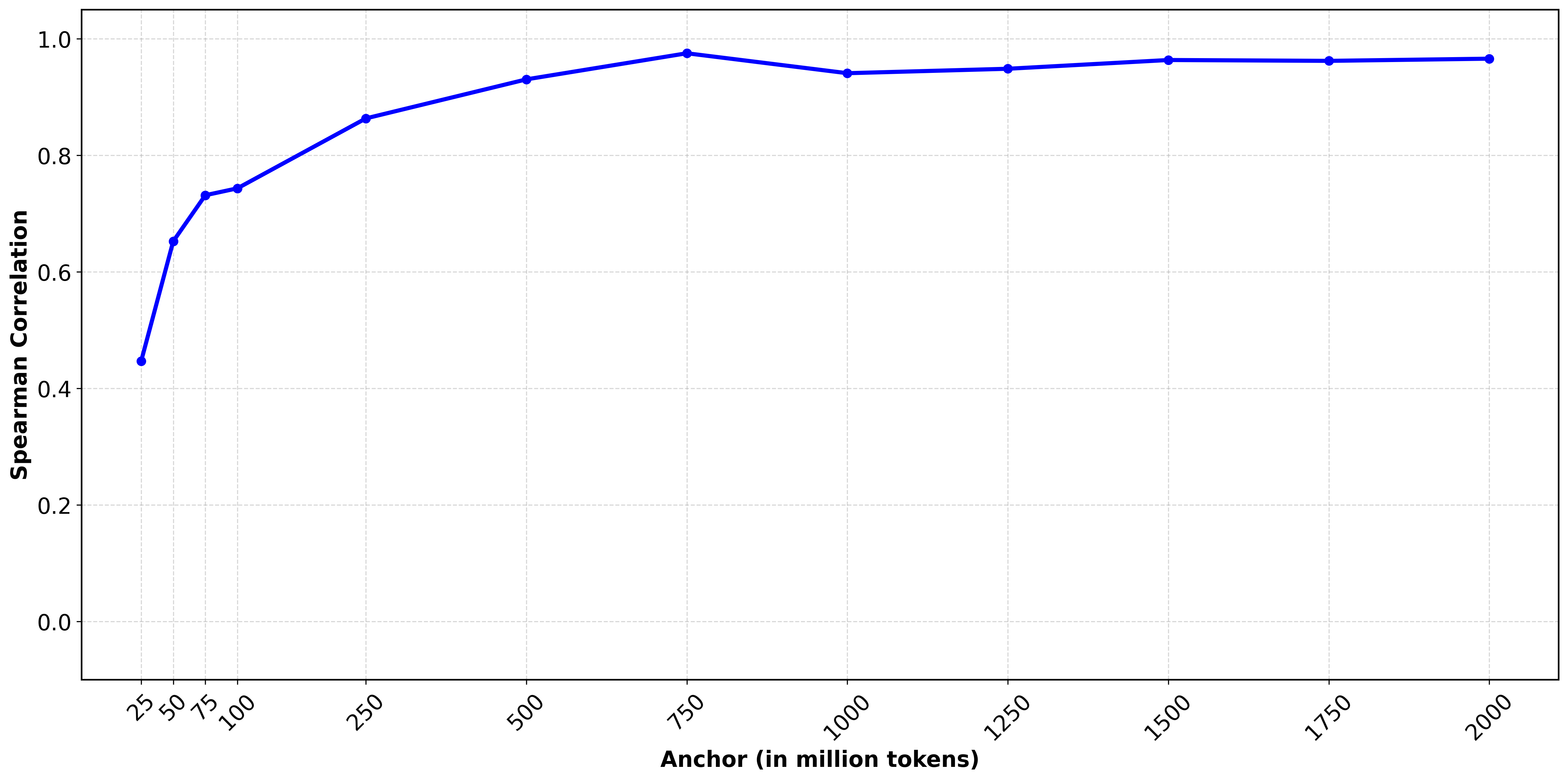
Early-anchor evaluations are strongly predictive of final behaviour, supporting compute-efficient early model discarding. Model rankings stabilise quickly across anchors, making early checkpoints useful for screening model-dataset combinations. By 250M tokens, Spearman rank correlation already exceeds 0.85, indicating that relative model ordering is largely established.
Reproducibility
- Pre-training and (upcoming)fine-tuning code
- Token-based checkpointing framework
- Model weights, logs, and learning curves
Repository: github.com/andreasparaskeva/lm-efficient-analysis
Citation
@article{paraskeva2026efficiency,
title={Efficiency in Language Model Pre-training: Learning Curves Across Datasets and Model Sizes},
author={Paraskeva, Andreas and van Duijn, Max Johannes and de Rijke, Maarten and Verberne, Suzan and van Rijn, Jan N.},
year={2026}
}